Submitted by Fatman on Wed, 07/11/2018 - 20:54
Permalink

I run various websites, and I keep a distant eye on which bits of them are popular and things like that. I'm always on the look out for anything that's not right, or any errors. I'd want to fix them; if you're going to have a website it needs to work properly so that people can use it, otherwise why bother?
The Hidden URL
A while back, I noticed something very odd. I was getting hits, every day or two, on a page on a website that only existed for my own purposes. It's purely private; in fact, unless you're logged into the website as me you'd get a 403 (forbidden) error. So the hits were not actually anyone viewing that webpage, but viewing an error when they tried to view it.
The URL for that particular page is not published anywhere. None of the search engines know about it. There are no links to it from anywhere else on that website, or any other website I run. So here was the question that was bothering me: How did this visitor know to visit that URL? How did they know it even existed?
The visits were coming from Russian IP addresses, such as 5.164.104.157 (amongst others). The User Agent made this look like any other regular visitor; they were using a modern web browser. Their referrer (the URL they came from) was something like this: http://yandex.ru/clck/jsredir?from=yandex.ru%3Bsearch%3Bweb%3B%3B&… In other words, they looked just like someone had clicked a link on the Russian search engine Yandex to get to me. Only they hadn't. Yandex hadn't got that page in their search index. Partly, they couldn't have (there was no link to it). Partly, I checked by searching.
Unwanted Intrusion
The only way this Russian visitor could know of that URL is if they had access to my browser history. That was a scary thought. You'd have thought that just knowing the URLs you visit don't reveal much about you. But there may be other times when I don't want someone to know every URL I visit, and the order in which I do so:
- If I had relied on "security by obscurity" to hide this particular private webpage, it would just have leaked. That's exactly why "security by obscurity" is never a good model, and why I used website authentication to lock it down.
- They could probably work out who I was, by noticing which websites I logged in admin side. They could then work out what products I was buying on various other websites. Some websites, such as forums, give away quite a lot if you look at the URLs that someone is visiting.
- Or take password reset URLs. You forget your password, so you get emailed a link that lets you reset your password. Whoever this was would immediately have access to that reset URL. If the website is properly set up, you'd only be able to use each URL once. But not all websites are properly set up.
There is no such thing as anonymised data.
For a whole host of reasons, I didn't want somebody in Russia building up a list of my entire web history.
Find the Guilty Extension
Time for a scientific test to find where the leak was from. I guessed it was one of the Chrome extensions I had installed.
One in particular had a checkbox to allow anonymous data to be sent back. I cleared the checkbox, knowing I'd never ticked it in the first place (such "features" should always be opt-in, not opt-out). I then changed the website script to modify the secret URL to a new one. And I waited.
Within a week, I was getting hits on that newly created URL.
I then put two and two together, and made 5. I got really annoyed with that Chrome extension. I assumed they weren't honouring the fact I'd not got the "send anonymous data" box ticked, and were filching my browser history anyway. I uninstalled the extension completely. Good riddance! And I changed the secret URL again.
A week passed, and my even more newly created URL wasn't being hit by the Russians. But after a fortnight, it started again. It wasn't that extension after all. Time to eat a good helping of 'umble pie.
And time to do some more detective work.
Enter Wireshark
I installed a piece of software called Wireshark
This is a packet sniffing tool for Windows. It allows you to monitor any network interface on your computer, to log the content of the traffic to and from the internet, to filter it on particular criteria, and so forth. It's insanely powerful, and I didn't wish to spend the time required to learn how to use it to the full.
I was able to learn enough to get it capturing traffic for a short period. So I turned on capturing, then loaded one very simple webpage with no images or other resources on, before immediately turning capturing off. I should only see traffic to and from the webserver for that page.
I filtered the data to get rid of any traffic to my own webserver. That left me with a few other IP addresses. There were three ways that this could have been really easy, but sadly it wan't to be.
- Wireshark doesn't tell you which programs or files on your computer were responsible for any given traffic. That would have led me very quickly to the culprit.
- It also doesn't capture the hostnames of the traffic (it can't see that your browser visits google.co.uk; it just sees the IP address at which you found Google).
- Almost all the traffic was encrypted. That's a shame. If the traffic had been plain-text, I could have searched for the URL I'd just visited to find out which request was leaking it. But that was not to be either.
So I had to work out who owned those IP addresses. Some were owned by Facebook and Google (for analytics and advertising).
Then I found two I didn't recognise; on looking them up, they were used by my antivirus provider, so they were just by antivirus suite checking the pages I was browsing were not phishing sites.
(That did leave me the slightly scary thought that my antivirus software could have been the leak; I hadn't considered that option. It turned out not to be them, but it does serve as a reminder to choose carefully whose software to install on your computer.)
That just left me with one final IP address.
From the IP to the Culprit
My web browser was sending traffic to 52.203.161.145, using TCP, connecting to remote port 443 (which means an https request).
How could I find out who was using this? Looking up the IP address, I could see it was assigned to Amazon for Amazon Web Services (AWS). That tells me nothing - someone is leasing a cloud VPS from AWS for this. The PTR (reverse DNS) record was just left at the default: ec2-52-203-161-145.compute-1.amazonaws.com. They weren't going to give away their identity that easily.
Then I had a thought. I knew that my browser was successfully communicating with them over port 443. So presumably https://52.203.161.145 works. Let's see what's there. Perhaps it will be a website that will give me a clue.
Instead, I got a browser warning that the webpage was insecure:
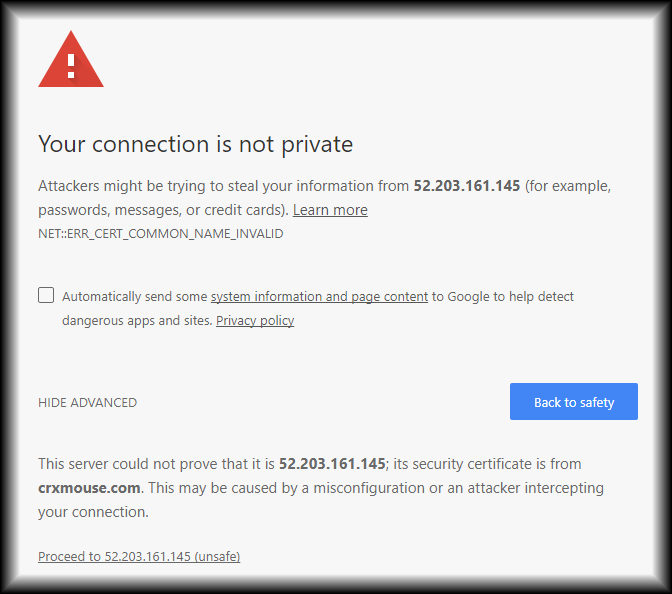
This was different from the security warning I wrote about two weeks ago. Always read the exact error message on a warning like this. Here's the bit that tells you what's going on:

The website was insecure. Why? I was browsing the website https://52.203.161.145, but the SSL certificate was for a different domain, crxmouse.com.
You'd never have guessed this just from the IP address. The domain crxmouse.com resolves to two addresses: 54.210.79.188 and 52.6.88.254, not to 52.203.161.145. But they didn't bother buying a new certificate for the server that receives the call-home requests, so the certificate's hostname gave the game away.
(Yes: I'm aware I've just told them how to hide better. So be it!)
Gotcha!
The Culprit
So, the culprit was the extension CrxMouse, which you install for Chrome here.
8 weeks ago now, I disabled the extension, and renamed that secret page's URL one final time. Since then, not one Russian bot has tried to load that page.
Let's have a look at the privacy policy for CrxMouse. (Interestingly, the privacy policy is on the page as a graphic, not as text, which means it can't be indexed. I wonder why they've done it in that unconventional fashion)
We primarily collect non-identifiable aggregated information ('Non-Personal Information'). This information is made available to us via your use of the Services. We are not aware of the identity of the users from whom the Non-Personal Information is collected. Non-Personal Information which is colleted includes the user's aggregated and technical information transmitted by the user's device or generated by the user's browser (e.g.: standard web server log information (i.e., web request) data sent in response to requests, and date and time stamp).
The Non-Personal Information is used to provide you with our Services, and to further improve, refine, customize and develop those Services. In addition, the Non-Personal Information is licensed to a third party for that third party's market and statistical analysis purposes and to conduct associated analytical activities and services. That third party is also unable to identify any individual users from the Non-Personal Information.
By the time we get to that last sentence, I'm thinking: Me thinks he doth protest too much.
Three lessons from all this
These terms are dishonest
As I said earlier, there is a distinction between saying that they don't transmit information about who the end-user is, and the much bigger claim that someone with that amount of data is unable to identify the individual users. The chances are that your browser history contains more than enough information for someone to identify you, and to do so relatively quickly.
Furthermore, they collect your full browser history. Why? Answer: "to provide you with our Services". This is an extension that captures mouse gestures to issue standard commands to the browser. None of this requires them to have any of the information they've just said they will collect. They are providing you with the Services of this Chrome extension. They are collecting all of this data. It is dishonest to say that they are collecting the data in order to provide the Services. They're not. They're collecting it for some other reason (for profit, probably).
Finally, they imply that the data they are collecting is data they would have anyway. It is "standard web server log information". This is data that any website operator would be able to collect from their server logs, as concerning pages you requested from their servers. They would not be able to gather any of this information concerning your visit to any other servers. For them to collect this data, for every website you visit (not just theirs), goes far beyond what information that is standard for you to give away. Yet they cast this policy in language that implies you're not really letting them do much. You are.
These terms matter
Answer me this: How many times have you been asked to tick that you agree (to some terms and conditions before visiting a website or downloaded some software), and you simply scrolled to the bottom and clicked "I agree"? I thought so. Me too.
A former colleague told me how he imagines a day at the end of his life when all the Ts and Cs you've ever agreed to are delivered to you. Several archive boxes, containing many box and lever-arch files of printouts. "There you are, Mr Oakley - these are the terms you agreed to during the course of your life."
But sometimes these things matter. There needs to be a sensible balance. Some website terms and conditions run to tens of thousands of words, and you can't read every bit closely and carefully. Learn how to use the headings to find your way around, learn how to scan up and down for things that may look alarming and need closer inspection. But the terms do matter, and only click "Yes" to the extent that you're happy to do so. The more data you'll be handing over, the more carefully you read.
These terms can change
Here's another problem with Chrome. It automatically updates extensions to the latest and greatest version. There are many extensions that used to be great, that became popular as a result, and that were then sold by the developers to new owners. Those new owners know that they are buying X end-users, who will automatically be upgraded to their new version. They can therefore bundle privacy-invading "features" in, and start capturing all that data, when none of that was ever what the original end-users agreed to.
Sadly this is a repeating pattern, and Chrome have not yet got to the bottom of how to stop it. So vigilence is key.
I could have searched
It turns out this is all well documented. There are pages about this on the ars Technica website, and on Life Hacker. A simple search would have led me to both. The latter even mentions CrxMouse as a culprit. It also mentions a new extension that warns you if any of your other extensions are exhibiting privacy-infringing behaviour. The link to that no longer works.
There's also a page, 4 years out of date now, on How-To Geek, entitled Warning: Your Browser Extensions Are Spying On You, that contains a list of such extensions.
Perhaps there is no neat solution for the need for vigilence, other than
- to search occasionally for the names of all the browser extensions you have installed, along with another search term such as "privacy" or "adware"
- to keep the number of browser extensions you use to an absolute minimum. Don't instantly load up Chrome with every bell and whistle; they're the weakpoint in Chrome's security and privacy, so use only as many as you need and are willing to keep an eye on.
Over to you
I hope this is helpful as a piece of thinking aloud about browser security, and also as a piece of detective work on tracking down a privacy leak. If this triggers any thoughts on tips and tricks, please share them below.
Blog Category:
Submitted by James Oakley on Wed, 07/11/2018 - 21:10
Permalink
Still looking
I'm yet to find one. :-(
If you (or anyone else) reading this knows of one that is provably clean, please suggest here. I miss being able to use the gestures to navigate more quickly.
Submitted by Fatman on Wed, 07/11/2018 - 21:17
Permalink
I did just now find someone's
I did just now find someone's github code for an extension:
https://github.com/iorate/uSuperDrag
The code is all there, and it doesn't do anything malicious. You can load it Unpacked, by turning on developer mode in the list of Extensions in chrome. But I have no idea if it really works well and what bugs might be lurking. It seems to do what the tin says...
Submitted by Enquirer on Thu, 31/01/2019 - 05:45
Permalink
Please test this
James, please test this supposed clean version of crxmouse
https://chrome.google.com/webstore/detail/clean-crxmouse-gestures/mjidkpedjlfnanainpdfnedkdlacidla
I'm suspect of this because crxmouse is not open-source.
Submitted by James Oakley on Thu, 31/01/2019 - 09:19
Permalink
No thanks
Like you, I'm wary because it's not open source.
1. The original crxmouse was not open source, and you can't fork a closed source project.
2. This new variant is also not open source, so I can't inspect it to see if it is any better. Also, the problem with crxmouse was that it started off clean but then had malware added into an upgrade. So it's not possible to see if this is still clean, even if it once was.
I'd feel more comfortable trying an extension that is new, rather than based on something known to be bad, preferably that is open source so has nothing to hide.
Submitted by Sucker on Sun, 13/10/2019 - 21:35
Permalink
theft
I think CrxMouse might be malicious. I received a gift certificate that required only the URL with a unique ID to claim it. I had first visited the gift certificate page to check the amount. When I went back a month later, the money was gone. I believe CrxMouse sent my browsing history to its publisher, and they used it to steal the money. Beware!
Add new comment
So what did you end up using for super-drag or mouse gesture functionality?